Exclude Columns - Detailed Specification
Feature available from Bizview version - Bizview 7.2
When using #plandata (like BV columns or BIZVIEW/#plandata) by executing dat.p_data_cells_populate and the table dat.data_cells contains a large amount of rows, the procedure may take long time to execute if the selection results in many rows. To improve performance and eliminate this behaviour, the designer can tell the procedure to exclude columns that are obsolete in the query. When excluding columns, Bizview will group the result and hopefully the result will contain fewer rows, and therefore, enhance performance when opening the report/form.
This topic contains the following sections:
How to Know When Exclude Columns can be Useful
If #plandata is taking long time to finish the designer should run the template with Trace (CTRL+SHIFT).
- Open the Trace window in the File menu.
- Click on the Plandata tab (after it has been generated).
- At the bottom, the output from the procedure can be viewed. Scroll down almost to the bottom and a similar text as this can be found:
insert into #plandata_
([data_cell_id], [batch_id], [CLIENT], [VERSION], [VALT], [CURR], [SPKEY], [SPVAL], [SPGROUP], [SPLIM], [TIMEUNIT], [TIMEVAL], [CVAL], [cellvalue_recalc], [ATTGROUP], [att_cluster_id], [dim_cluster_id], [ws_name], [ws_row], [ws_col], [comment], [upd_user_id], [updated], [is_formula], [form_tag], [template_id], KONTSPE, AVDFRA, VKAT, RENSVAR, KONTO, SELGER, ANSVARSSTED, VKAT1, VKAT2, RENSVARGR, LINJENR, AVDELING, DIVISJON, FOMR, LPVERDI, REGION, STRNR6, VERDIKJEDE, EXCEL, LINJENR_AT, FORD1, FORD2, FORD3, FORD4, FORD5, FORD6)
select dc.[data_cell_id], dc.[batch_id], dc.[client_id], dc.[version_id], dc.[valtype_id], dc.[currcode_id], dc.[spreadkey_id], dc.[spreadvalue], dc.[spreadgroup], dc.[spreadlimit], dc.[timeunit_id], dc.[timeval_id], dc.[cellvalue], dc.[cellvalue_recalc], dc.attribgroup, dc.att_cluster_id, dc.dim_cluster_id, dc.[ws_name], dc.[ws_row], dc.[ws_col], dc.[comment], dc.[upd_user_id], dc.[updated], dc.[is_formula], dc.[form_tag], dc.[template_id], cl.KONTSPE, cl.AVDFRA, cl.VKAT, cl.RENSVAR, cl.KONTO, cl.SELGER, cl.ANSVARSSTED, cl.VKAT1, cl.VKAT2, cl.RENSVARGR, cl.LINJENR, cl.AVDELING, cl.DIVISJON, cl.FOMR, cl.LPVERDI, cl.REGION, cl.STRNR6, cl.VERDIKJEDE, cl.EXCEL, cl.LINJENR_AT, cl.FORD1, cl.FORD2, cl.FORD3, cl.FORD4, cl.FORD5, cl.FORD6
from dat.data_cells dc
inner join #flattened_data_dim cl on cl.dim_cluster_id = dc.dim_cluster_id
*** Execution time: 826923 (Elapsed: 907730) ********************** TIME CONSUMING SQL ***
*** Records affected: 932031
As you can see, the insert resulted in 932031 records and the execution time was 826 seconds (almost 14 minutes). In this case, it's probably a good idea to exclude columns that are not needed.
How to Exclude Columns from the Query
- Open the template in which columns should be excluded.
- Go to Parameters tab in the Properties panel to the right.
- Expand the section SQL - Alter SQL query.
- Click the Exclude Columns button (go to EXCLUDE_COLUMNS to view the location of the button)
The following dialog will become visible:
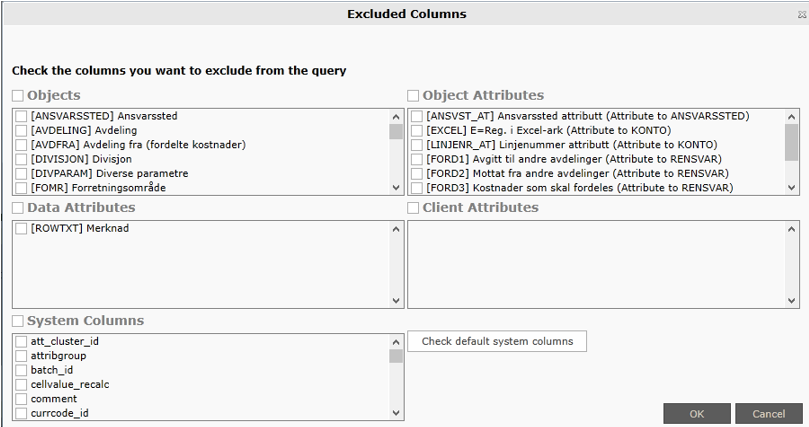
The dialog shows all objects, object attributes, data attributes, client attributes, and system columns. Bizview does not evaluate anything from the template, so it's up to the designer to exclude the correct columns.
When #plandata executes it will collect all objects that exist in the template and add all objects that exist in the same object tree. Bizview will also add the attributes for the objects and add data attribute and client attribute to the query. For this reason, some objects and attributes in the dialog above will never be retrieved by Bizview and these columns are therefore obsolete for this particular template; it doesn't matter if they are checked or unchecked.
In the query above (marked with yellow) you can see which objects and attributes that are retrieved from the query. Those are:
KONTSPE, AVDFRA, VKAT, RENSVAR, KONTO, SELGER, ANSVARSSTED, VKAT1, VKAT2, RENSVARGR, LINJENR, AVDELING, DIVISJON, FOMR, LPVERDI, REGION, STRNR6, VERDIKJEDE, EXCEL, LINJENR_AT, FORD1, FORD2, FORD3, FORD4, FORD5, FORD6
Which Columns Should be Unchecked/Checked?
Objects and attributes that exist in the template area should NEVER be checked.
These are, for example:
Columns defined at row 1.
Objects and attributes in column A.
Objects and attributes that exists in the SEARCHVAL column.
Columns that can be checked are, for example:
Object and attributes only existing in PARAM
Objects and attributes that exist in PARAM can be checked. For example, if you have KONTO in PARAM, Bizview will exclude that column ONLY if there is no selection by that object (the value is blank, * or %). If there is a value, like 30*, Bizview will NOT exclude the column because it will be needed to run the form/report. This particular behaviour is automatically handled by Bizview, which means that every object and attribute that ONLY exist in PARAM can be checked.
All other objects and attributes that do NOT exist anywhere in the template.
System columns.
As can be viewed in the dialog above, the list at the bottom contains the system columns defined in dat.data_cells. Upon selecting Check default system columns, Bizview will check the columns that probably won't be needed.
After Columns are Excluded in the Template
When #plandata procedure executes it will exclude the columns that the designer has checked. The result will still be 932031. But since columns are excluded from the insert, Bizview will now try to group the result on all columns. It is probable that many of the rows have the same values and can be grouped together. If running the template with trace again, we can conclude the following:
insert into #plandata_
([CLIENT], [VERSION], [VALT], [CURR], [SPKEY], [SPGROUP], [SPLIM], [TIMEUNIT], [TIMEVAL], [ATTGROUP], [comment], [form_tag], [KONTSPE], [KONTO], [LINJENR], CVAL, SPVAL )
select dc.[client_id], dc.[version_id], dc.[valtype_id], dc.[currcode_id], dc.[spreadkey_id], dc.[spreadgroup], dc.[spreadlimit], dc.[timeunit_id], dc.[timeval_id], dc.attribgroup, dc.[comment], dc.[form_tag], cl.[KONTSPE], cl.[KONTO], cl.[LINJENR], SUM(dc.cellvalue), MAX(dc.spreadvalue)
from dat.data_cells dc
inner join #flattened_data_dim cl on cl.dim_cluster_id = dc.dim_cluster_id
group by dc.[client_id], dc.[version_id], dc.[valtype_id], dc.[currcode_id], dc.[spreadkey_id], dc.[spreadgroup], dc.[spreadlimit], dc.[timeunit_id], dc.[timeval_id], dc.attribgroup, dc.[comment], dc.[form_tag], cl.[KONTSPE], cl.[KONTO], cl.[LINJENR]
*** Execution time: 6960 (Elapsed: 25686) ********************** TIME CONSUMING SQL **********************
*** Records affected: 10043
You can see that only [KONTSPE], [KONTO], [LINJENR] have been selected and a group by has been added. By doing this, the insert went from 826 seconds (almost 14 minutes) to 7 seconds.
Note: It is up to the designer to evaluate which columns can be excluded and how that affects the report/form. Run the report/form with trace before and after excluding columns to ensure the correct result.